
Trong khi “người anh em” Gemini 2.5 Pro vẫn đang dẫn đầu về khả năng sáng tạo, thì mới đây, Google bất ngờ tung ra Gemini 2.5 Flash ngay trong ứng dụng Gemini một mô hình AI có khả năng lý luận khá tốt, nhưng điểm khác biệt là nó cho phép người dùng kiểm soát khá linh hoạt cách mà mô hình “suy nghĩ”.
Bạn có thể tùy chỉnh để cân bằng giữa chất lượng phản hồi, tốc độ xử lý và chi phí sao cho phù hợp với từng công việc cụ thể. Nó được tối ưu cho hiệu suất và chi phí
Gemini 2.5 Flash được thiết kế để hoạt động hiệu quả mà vẫn tiết kiệm chi phí. Điều này khá hữu ích cho các ứng dụng cần xử lý nhiều yêu cầu hoặc cần phản hồi nhanh, ví dụ như các hệ thống chatbot, tóm tắt thông tin tự động, hay phân tích dữ liệu đa dạng (văn bản, hình ảnh, video, âm thanh).
Các tính năng cốt lõi và cải tiến trong Gemini 2.5 Flash
Gemini 2.5 Flash giới thiệu một loạt các tính năng sáng tạo giúp nó trở thành một công cụ mạnh mẽ cho các ứng dụng AI hiện đại. Các khả năng này nâng cao tính linh hoạt, hiệu quả và hiệu suất của nó, khiến nó phù hợp với nhiều trường hợp sử dụng khác nhau trong nhiều ngành. Hiện tại dữ liệu của Gemini 2.5 Flash được cập nhật đến khoảng tháng 1 năm 2025.
Lý luận đa phương thức và tích hợp công cụ gốc
Gemini 2.5 Flash xử lý văn bản, hình ảnh, âm thanh và video trong một hệ thống thống nhất, cho phép phân tích nhiều loại dữ liệu khác nhau cùng nhau mà không cần chuyển đổi riêng biệt. Khả năng này cho phép AI xử lý các đầu vào phức tạp, chẳng hạn như quét y tế kết hợp với báo cáo xét nghiệm hoặc biểu đồ tài chính kết hợp với báo cáo thu nhập.
Một tính năng chính của mô hình này là khả năng thực hiện các tác vụ trực tiếp thông qua tích hợp công cụ gốc. Nó có thể tương tác với API cho các tác vụ như truy xuất dữ liệu, thực thi mã và tạo ra các đầu ra có cấu trúc như JSON, tất cả mà không cần dựa vào các công cụ bên ngoài. Hơn nữa, Gemini 2.5 Flash có thể kết hợp dữ liệu trực quan, chẳng hạn như bản đồ hoặc sơ đồ luồng, với văn bản, tăng cường khả năng đưa ra quyết định có nhận thức theo ngữ cảnh. Ví dụ: Palo Alto Networks đã sử dụng khả năng đa phương thức này để cải thiện khả năng phát hiện mối đe dọa bằng cách phân tích nhật ký bảo mật, mô hình lưu lượng mạng và nguồn cấp dữ liệu tình báo về mối đe dọa cùng nhau, mang lại thông tin chi tiết chính xác hơn và ra quyết định tốt hơn.
Tối ưu hóa độ trễ động
Một trong những tính năng nổi bật của Gemini 2.5 Flash là khả năng tối ưu hóa độ trễ một cách linh hoạt thông qua khái niệm suy nghĩ ngân sách. Ngân sách suy nghĩ tự động điều chỉnh dựa trên độ phức tạp của tác vụ. Mô hình này được thiết kế cho các ứng dụng có độ trễ thấp, lý tưởng cho các tương tác AI thời gian thực. Trong khi thời gian phản hồi chính xác phụ thuộc vào độ phức tạp của tác vụ, Gemini 2.5 Flash ưu tiên tốc độ và hiệu quả, đặc biệt là trong môi trường có khối lượng lớn.
Ngoài ra, Gemini 2.5 Flash hỗ trợ cửa sổ ngữ cảnh 1 triệu token, cho phép xử lý lượng dữ liệu lớn trong khi vẫn duy trì độ trễ dưới một giây cho hầu hết các truy vấn. Khả năng ngữ cảnh mở rộng này nâng cao khả năng xử lý các tác vụ lý luận phức tạp, biến nó thành một công cụ mạnh mẽ cho các doanh nghiệp và nhà phát triển.
Kiến trúc lý luận nâng cao
Dựa trên những tiến bộ của Gemini 2.0 Flash, Gemini 2.5 Flash tiếp tục nâng cao khả năng suy luận của mình. Mô hình sử dụng suy luận nhiều bước, cho phép xử lý và phân tích thông tin theo từng giai đoạn, cải thiện độ chính xác khi ra quyết định. Ngoài ra, nó sử dụng cắt tỉa theo ngữ cảnh để ưu tiên các điểm dữ liệu có liên quan nhất từ các tập dữ liệu lớn, tăng hiệu quả ra quyết định.
Một tính năng quan trọng khác là chuỗi công cụ, cho phép mô hình tự động thực hiện các tác vụ nhiều bước bằng cách gọi API bên ngoài khi cần. Ví dụ, mô hình có thể lấy dữ liệu, tạo hình ảnh trực quan, tóm tắt các phát hiện và xác thực số liệu, tất cả đều không cần sự can thiệp của con người. Các khả năng này hợp lý hóa quy trình làm việc và cải thiện đáng kể hiệu quả chung.
Hiệu quả tập trung vào nhà phát triển
Gemini 2.5 Flash được thiết kế cho các ứng dụng AI có khối lượng lớn, độ trễ thấp, rất phù hợp với các tình huống cần xử lý nhanh. Mô hình này có sẵn trên Vertex AI của Google, đảm bảo khả năng mở rộng cao cho mục đích sử dụng của doanh nghiệp.
Các nhà phát triển có thể tối ưu hóa hiệu suất AI thông qua Model Optimizer của Vertex AI, giúp cân bằng chất lượng và chi phí, cho phép các doanh nghiệp điều chỉnh khối lượng công việc AI một cách hiệu quả. Ngoài ra, các mô hình Gemini hỗ trợ các định dạng đầu ra có cấu trúc, chẳng hạn như JSON, cải thiện khả năng tích hợp với nhiều hệ thống và API khác nhau. Cách tiếp cận thân thiện với nhà phát triển này giúp triển khai tự động hóa do AI điều khiển và phân tích dữ liệu nâng cao dễ dàng hơn.
Tính năng “Thinking Budget”
Tính năng đáng chú ý nhất có lẽ là “thinking budget” (ngân sách suy nghĩ). Nó cho phép người dùng hoặc lập trình viên điều chỉnh mức độ “đào sâu suy nghĩ” (reasoning) của AI. Bạn có thể đặt mức này từ 0 (tốc độ và chi phí tương đương bản Flash 2.0 trước đó) lên đến tối đa khoảng 24.576 token. Hoặc bạn cũng có thể để AI tự quyết định dựa trên độ phức tạp của yêu cầu đầu vào.
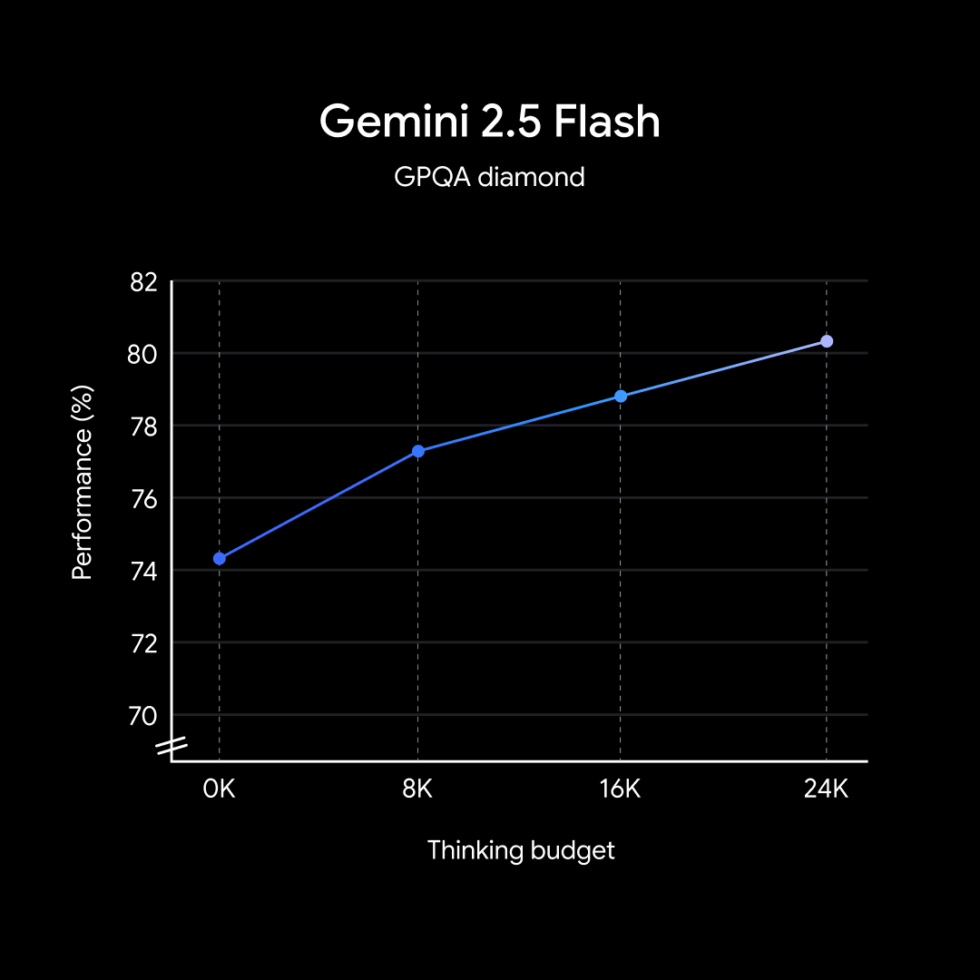
Nhờ vậy, mô hình này có thể xử lý được nhiều loại tác vụ, từ những câu hỏi đơn giản (“Cách nói cảm ơn trong tiếng Tây Ban Nha?”) đến những việc cần nhiều bước xử lý, lập kế hoạch, hay phân tích dữ liệu phức tạp hơn. Khi bạn tăng mức “ngân sách suy nghĩ”, chất lượng và độ chính xác của kết quả thường sẽ tăng lên, hữu ích cho các việc cần sự tỉ mỉ, nhưng chi phí cũng sẽ cao hơn một chút.
So với các mô hình có khả năng “suy nghĩ” khác của Google, Gemini 2.5 Flash hiện là lựa chọn tiết kiệm nhất. Giá đầu ra mặc định (khi không bật tính năng reasoning) là $0.60 cho mỗi 1 triệu token. Khi bạn bật chế độ reasoning sâu hơn, giá sẽ là $3.50 cho 1 triệu token. Người dùng có thể chủ động quản lý chi phí này bằng cách điều chỉnh mức “ngân sách suy nghĩ” cho phù hợp.
Gemini 2.5 Flash Preview 04-17 là một lựa chọn đáng cân nhắc cho các doanh nghiệp, nhà phát triển, hoặc cả người dùng cá nhân đang tìm kiếm một công cụ AI đa dụng, linh hoạt, tiết kiệm chi phí mà vẫn đảm bảo hiệu quả cho các công việc cụ thể.